Please ensure you adhere to the following guidelines before using the Probability Density Function toolkit:
File Naming
Rename your CSV file to match the plant section being analyzed:
CementAPCToolKit_RawMill.csv
CementAPCToolKit_CoalMill.csv
CementAPCToolKit_Kiln.csv
CementAPCToolKit_CementMill.csv
Header & Column Formatting
Include a single header row with clear labels for all dependent and independent variables.
Replace spaces with underscores (e.g., Elevator_Load rather than Elevator Load).
Omit units from column names; units should not be embedded in the header.
Ensure the feed column is labeled Total_Feed.
Columns may appear in any order.
Data Formatting
Follow the formatting conventions illustrated in the provided screenshot (consistent delimiters, no embedded units, etc.).
Upload
Click Select file, choose your preprocessed CSV, then click Upload.
Run Analysis
Once the upload completes, click Run to execute the toolkit.
When prompted, specify the plant section by entering one of:
(Use the exact suffix matching your file’s name.)
If you encounter any issues:
Navigate to Contact, complete the contact form, and we will respond promptly.
Alternatively, email us at [email protected].
By following these steps, you will ensure a seamless experience and accurate PDF–based analysis.


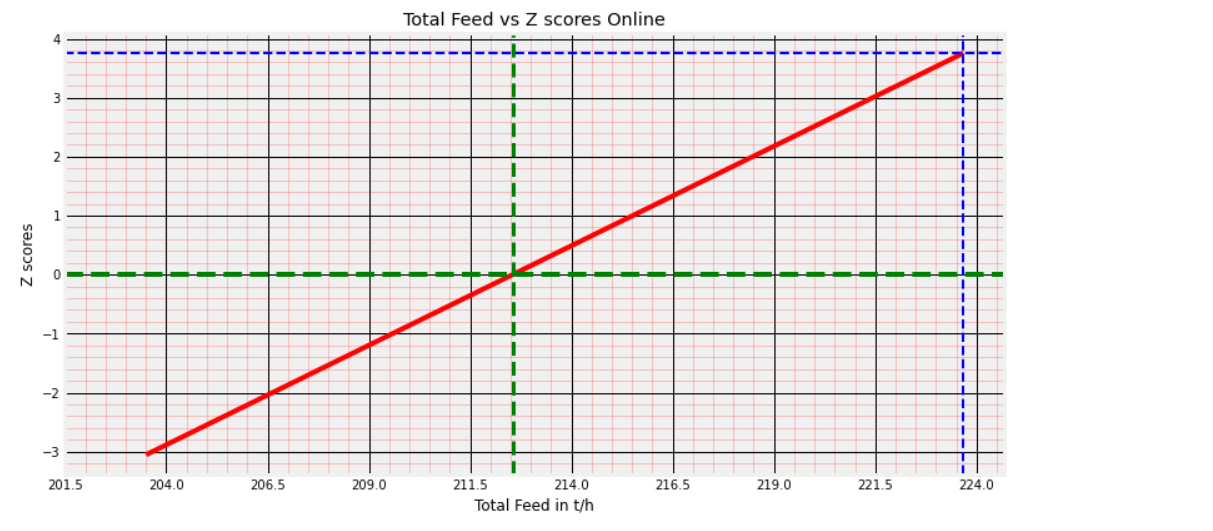
Probability Density Function of Total Feed and its Z-score density distribution.
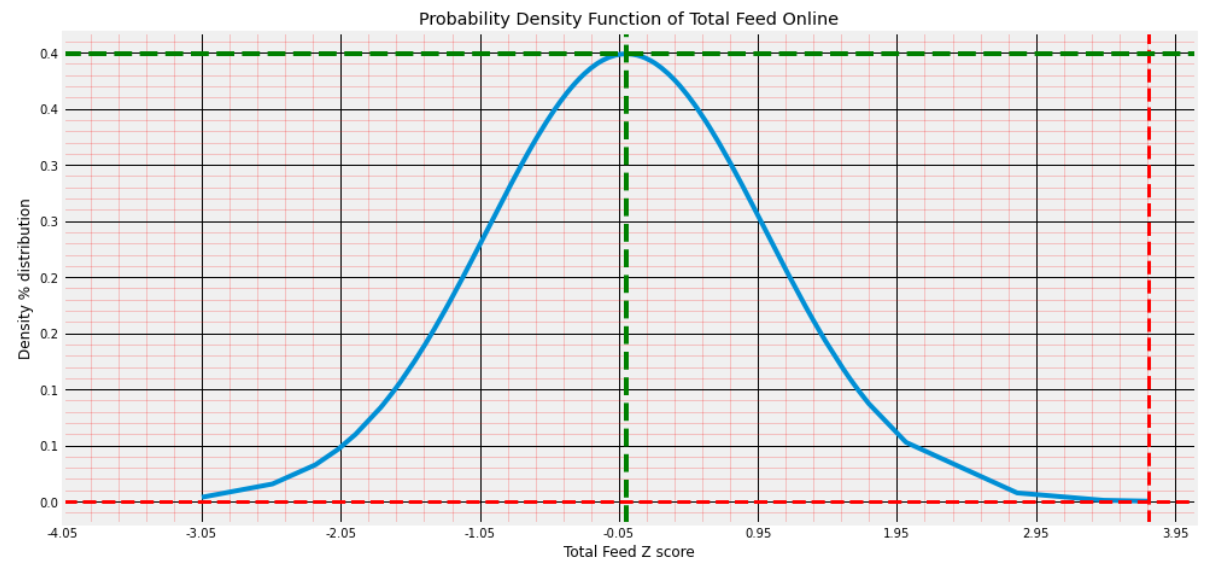
Total Feed vs Z-scores: To trace the % distribution of Total Feed samples from the PDF curve.